HTTP 완벽 가이드 1장: HTTP 개관

목차마다 무엇을 알아야하는지 정리
목차
1장 키워드들
- HTTP
- 웹 리소스
- MIME 타입
- URI, URL, URN
- HTTP 메시지
- Request(시작줄, 헤더, 본문)
- Response(상태줄, 헤더, 본문)
- 메서드, 상태코드
- TCP 커넥션
- 프로토콜 버전
- 웹 구성요소
- 프록시, 캐시, 게이트웨이, 터널, 에이전트
1. HTTP
📝3-4p, HTTP MDN
HTTP에 대해서 대략적으로 설명할 수 있으면 이 섹션을 건너뛰어도 좋습니다.
HTTP(HyperText Transfer Protocol) = 하이퍼미디어 문서를 전송하기위한 애플리케이션 레이어 프로토콜, 서버와 클라이언트 사이간의 메시지 통신 규약
- 웹 브라우저와 웹 서버간의 커뮤니케이션을위해 디자인되었지만, 다른 목적으로도 사용가능
- HTTP는 클라이언트가 요청을 생성하기 위한 연결을 연다음 응답을 받을때 까지 대기하는 전통적인 클라이언트-서버 모델을 따름
2. 웹 리소스
📝5p, MIME_Types MDN
‘웹 리소스’에 대해서 대략적으로 설명할 수 있으면 이 섹션을 건너뛰어도 좋습니다.
웹 리소스 = HTTP 요청 대상
- 리소스의 특성은 더 이상 정의되지 않음(어떤 컨텐츠 등 가능)
- 정적 리소스(ex. text, html, word, pdf 등)
- 동적 리소스(ex. 게이트웨이)도 포함
3. MIME 타입
📝6p. MIME 타입 MDN, 뒷장에서 더 설명되서 자세한 내용은 생략
‘MIME 타입’에 대해서 대략적으로 설명할 수 있으면 이 섹션을 건너뛰어도 좋습니다.
MIME(Multipurpose Internet Mail Extensions) = 클라이언트에게 전송된 문서의 다양성을 알려주기 위한 메커니즘
- 웹에서 파일의 확장자는 별 의미가 없음
- 각 문서와 함께 올바른 MIME 타입을 전송하도록, 서버가 정확히 설정하는 것이 중요
- 브라우저들은 리소스를 내려받았을 때 해야 할 기본 동작이 무엇인지를 결정하기 위해 사용
- 주 타입(Prmiary object type)/부 타입(Specific subtype)으로 구성
- ex. text/html, image/jpeg, audio/mpeg, video/mpeg, application/pdf
- MIME 타입 전체 목록은 📝부록D 혹은 MIME 전체목록 MDN를 참고
- MIME 타입은 대소문자를 구분하지는 않지만 전통적으로 소문자로 쓰여짐
4. URI vs URL
📝7-8p, URL과 URN MDN
‘URI’, ‘URL’, ‘URN’에 대해서 관하여 설명할 수 있으면 이 섹션을 건너뛰어도 좋습니다.
URI(Uniform Resource Identifier) = 하나의 리소스를 가리키는 문자열
가장 흔한 URI는 URL로, 웹 상에서의 위치로 리소스를 식별
식별(URI)과 위치(URL)의 차이라고 보면 되지 않을까 싶네요…
MDN문서에서도 굳이 이 차이에 대해서 설명하지 않고 있어, 이 부분은 생략하겠습니다.
- URN은 주어진 이름공간 안의 이름으로 리소스를 식별
- ex
urn:isbn:0451450523 - 책에서는 아직 널리 채택되지않은 기술이라고 언급하고 있지만, 현재는 rfc3986에서 확인한 결과
INTERNET STANDARD상태이다. - 주소가 바뀌는 것과 상관없이 사용할 수 있는 것이 특성
- ex
5. HTTP 메시지
📝9-13p, HTTP 메시지 MDN
HTTP 메시지 구성 및 방식에 대해서 설명할 수 있으면 이 섹션을 건너뛰어도 좋습니다.
- 클라이언트와 서버는 HTTP 메시지를 주고받음
- HTTP 메시지 = HTTP 메시지는 서버와 클라이언트 간에 데이터가 교환되는 방식
- 메시지 타입은 두 가지
- 요청(request) = 클라이언트가 서버로 전달해서 서버의 액션이 일어나게끔 하는 메시지
- 응답(response) = 요청에 대한 서버의 답변
HTTP 요청
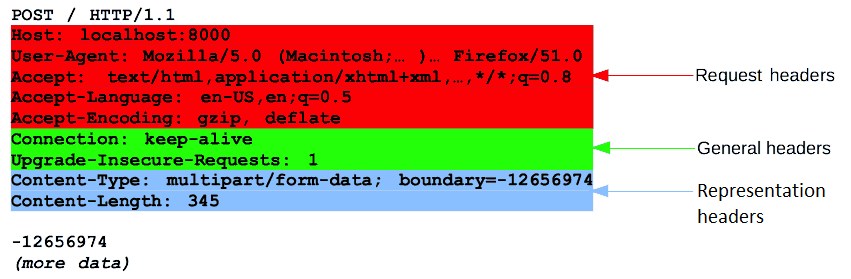
- HTTP 요청은 시작줄, 헤더, 본문으로 구성
시작줄(start-line)
- 첫번째로 오는 것은
HTTP 메서드로, 영어 동사(GET, PUT,POST) 혹은 명사(HEAD, OPTIONS)를 사용해 서버가 수행해야 할 동작 표시 - 두번째로 오는 요청 타겟은 주로 URL
- origin 형식: 끝에
'?'와 쿼리 문자열이 붙는 절대 경로- ex.
GET /background.png HTTP/1.0
- ex.
- absolute 형식: 완전한 URL 형식
- 프록시에 연결하는 경우 대부분 GET과 함께 사용
- ex.
GET http://developer.mozilla.org/ HTTP/1.1
- origin 형식: 끝에
- …
- authority 형식: 도메인 이름 및 옵션 포트(‘:’가 앞에 붙음)로 이루어진 URL의 authority component
- HTTP 터널을 구축하는 경우에만 CONNECT와 함께 사용
- ex.
CONNECT developer.mozilla.org:80 HTTP/1.1
- asterisk 형식: OPTIONS와 함께 별표(‘*’) 하나로 간단하게 서버 전체를 표시
- ex. OPTIONS * HTTP/1.1
- authority 형식: 도메인 이름 및 옵션 포트(‘:’가 앞에 붙음)로 이루어진 URL의 authority component
- 마지막으로 HTTP 버전을 표시
- ex.
HTTP/1.1
- ex.
헤더(header)
- 요청에 들어가는 HTTP 헤더는 HTTP 헤더의 기본 구조를 따름
- 대소문자 구분없는 문자열 다음에 콜론(‘:’)이 붙음
- 다양한 종류의 요청 헤더
- General 헤더:
Via와 같은 헤더는 메시지 전체에 적용 - Request 헤더:
User-Agent또는Accept와 같은 헤더 - Representation 헤더:
Content-Type와 같은 헤더
- General 헤더:
본문(body)
- 모든 요청에 본문이 들어가지는 않음
GET,HEAD,DELETE,OPTIONS리소스를 가져오는 요청은 보통 본문이 필요없음- 넓게 보면 본문은 두가지 종류
- 단일-리소스 본문(single-resource bodies): 헤더 두 개(
Content-Type와Content-Length)로 정의된 단일 파일로 구성 - 다중-리소스 본문(multiple-resource bodies): 멀티파트 본문으로 구성되는 다중 리소스 본문에서는 파트마다 다른 정보를 지니게 됩니다. 보통 HTML 폼과 관련
- 단일-리소스 본문(single-resource bodies): 헤더 두 개(
HTTP 응답
상태줄(Status Line)
- HTTP 응답의 시작 줄은 상태 줄(status line)이라고 불림
- 프로토콜 버전: ex.
HTTP/1.1 - 상태 코드: 요청의 성공 여부
- 상태 텍스트: 짧고 간결하게 상태 코드에 대한 설명을 글로 나타내어 사람들이 HTTP 메시지를 이해할 때 도움
- HTTP 2부터는 사유 구절(reason phrase)이 제거됨
- ex.
HTTP/1.1 404 Not Found
- 시작줄과 다른 점은 요청타겟 대신 상태코드가 3자리 숫자로 구성되어 표시 (전체목록 참조)
- 1xx: 정보 응답
- 2xx: 성공
- 3xx: 리다이렉션
- 4xx: 클라이언트 오류
- 5xx: 서버 오류
- 프로토콜 버전: ex.
헤더(header): Request Header와 동일
본문(body)
- 모든 응답에 본문이 들어가지는 않음(
201,204과 같은 상태 코드를 가진 응답에는 보통 본문이 없음) - 넓게 3가지 종류로 구분
- 이미 길이가 알려진 단일 파일로 구성된 단일-리소스 본문: 헤더 두개(
Content-Type와Content-Length)로 정의 - 길이를 모르는 단일 파일로 구성된 단일-리소스 본문:
Transfer-Encoding가chunked로 설정되어 있으며, 파일은 청크로 나뉘어 인코딩 - 서로 다른 정보를 담고 있는 멀티파트로 이루어진 다중 리소스 본문
- 이미 길이가 알려진 단일 파일로 구성된 단일-리소스 본문: 헤더 두개(
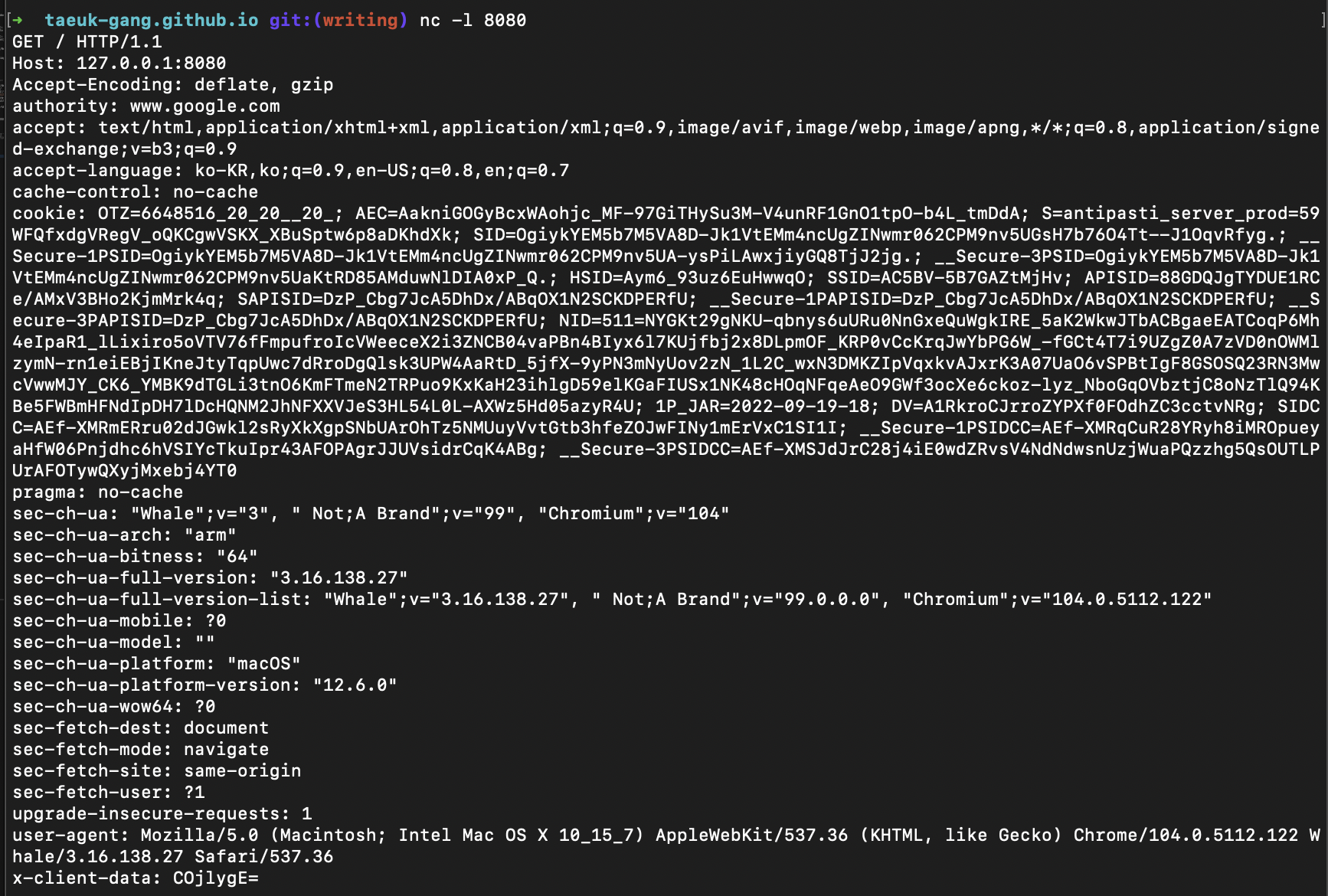
책 내용 외 추가작성. chrome 개발자도구에서는 HTTP Raw Message를 확인할 수 없다. 그렇다면 어떻게 확인할 수 있을까?
네트워크 패널에서 확인하고 싶은 요청의 curl을 복사(copy)
터미널을 열고
nc -l 8080(임의포트)실행
(요즘은telnet대신nc를 사용하는 추세)- Netcat(ornc)은 TCP 또는 UDP 프로토콜을 사용하여 네트워크 연결을 통해 데이터를 읽고 쓰는 명령줄 유틸리티
- 일반적으로 상대 서버의 포트가 열렸는지 확인하거나, 직접 서버가 되어 원격 서버에서(클라이언트) 접속이 가능하지 확인하는 용도로 사용
복사한 curl을 붙여넣기(paste)하고
--raw -i옵션을 추가하여 실행nc가 실행된 터미널에서 HTTP 메시지 확인 가능
6. TCP 커넥션
📝13-18p.
HTTP 어플리케이션 계층과 TCP 데이터 전송 계층을 이해했다면 이 섹션을 건너뛰어도 좋습니다.
- HTTP는 애플리케이션 계층 프로토콜로 네트워크 통신 핵심적인 세부적인 사항에 대해서 처리를 하지는 않음
- 대신 대중적이고 신뢰성 있는 TCP/IP에게 그 역할을 맡김
- 이 책에서 설명하는 TCP 특징
- 오류 없는 데이터 전송(신뢰성)
- 언제나 보낸 순서대로 도착
- 언제든 어떤 크기로든 보낼 수 있음
- 이 책에서 설명하는 TCP 특징
- HTTP 프로토콜 5계층
- HTTP (어플리케이션 계층)
- TCP (전송 계층)
- IP (네트워크 계층)
- Ethernet (네트워크 인터페이스 계층)
- 물리 계층
- 네트워크를 설명할 때 넘어갈 수 없는 것이 OSI 7계층, OSI 자체는 현재 사용되진 않지만 참조 모델로 주로 사용
- 1계층 물리 계층: 전기적, 기계적, 기능적인 특성을 이용해 데이터를 전송
- 2계층 데이터 링크 계층: 물리 계층을 통해 송수신되는 정보의 오류와 흐름을 관리
- 3계층 네트워크 계층: 네트워크 통신 경로 선택
- 4계층 전송 계층: 네트워크 통신 관리
- 5계층 세션 계층: 통신 시작과 종료 순서
- 6계층 표현 계층: 데이터의 표현 방법을 정의
- 7계층 응용 계층: 사용자의 요구를 만족시키는 응용 서비스를 제공
- TCP/IP를 설명할 때는 보통 4계층으로 묶어서 설명
애플리케이션(5-7계층), 전송(4계층)
네트워크(3계층), 링크 계층(1-2계층)
7. 프로토콜 버전
📝18-19p. HTTP의 진화 MDN
HTTP 버전간의 차이를 설명할 수 있다면 이 장을 생략
- HTTP 초기 버전에는 버전 번호가 없었음
- 0.9부터 버전 관리를 시작
- HTTP/0.9 – 원-라인 프로토콜
- 요청은 단일 라인으로 구성
- 가능한 메서드는
GET이 유일 - HTTP 헤더가 없었는데 이는 HTML 파일만 전송될 수 있으며 다른 유형의 문서는 전송될 수 없음을 의미
- 문제가 발생한 경우, 특정 HTML 파일이 사람이 처리할 수 있도록, 해당 파일 내부에 문제에 대한 설명과 함께 되돌려 보내짐
- HTTP/1.0 – 확장성 만들기 - RFC 1945에 공개
- 버전 정보가 각 요청 사이내로 전송 ex.
GET HTTP/1.0 - 상태 코드 라인 또한 응답의 시작 부분에 붙어 전송 (브라우저가 요청에 대한 성공과 실패를 알 수 있음)
- HTTP 헤더 개념은 요청과 응답 모두를 위해 도입
- 버전 정보가 각 요청 사이내로 전송 ex.
일반적인 요청 예시
1 | GET /mypage.html HTTP/1.0 |
- 현재 가장 널리 사용되는 HTTP 버전
- 커넥션이 재사용 가능 (keep-alive: Three-shake 오버헤드를 줄임)
- 파이프라이닝을 추가(첫번째 요청에 대한 응답이 완전히 전송되기 이전에 두번째 요청 전송을 가능케 하여, 커뮤니케이션 레이턴시를 낮춤)
- 청크된 응답 또한 지원
- 추가적인 캐시 제어 메커니즘이 도입
- 캐시 제어 메커니즘에 대한 내용은 이곳에서 확인 가능
- 언어, 인코딩 혹은 타입을 포함한 컨텐츠 협상이 도입
Host헤더 덕분에, 동일 IP 주소에 다른 도메인을 호스트하는 기능이 서버collocation을 가능
- HTTP/2 – 더 나은 성능을 위한 프로토콜
- 텍스트 프로토콜이라기 보다는 이진 프로토콜 (더 이상 읽을 수도 없고 수작업을 만들어낼 수 없음)
- 병렬 요청이 동일한 커넥션 상에서 다루어질 수 있는 다중화 프로토콜
(순서를 제거해주고 HTTP/1.x 프로토콜의 제약사항을 막음) - 전송된 데이터의 분명한 중복과 그런 데이터로부터 유발된 불필요한 오버헤드를 제거
(연속된 요청 사이의 매우 유사한 내용으로 존재하는 헤더들을 압축) - 서버로 하여금 사전에 클라이언트 캐시를 서버 푸쉬라고 불리는 메커니즘, 필요한 데이터 채우기 허용
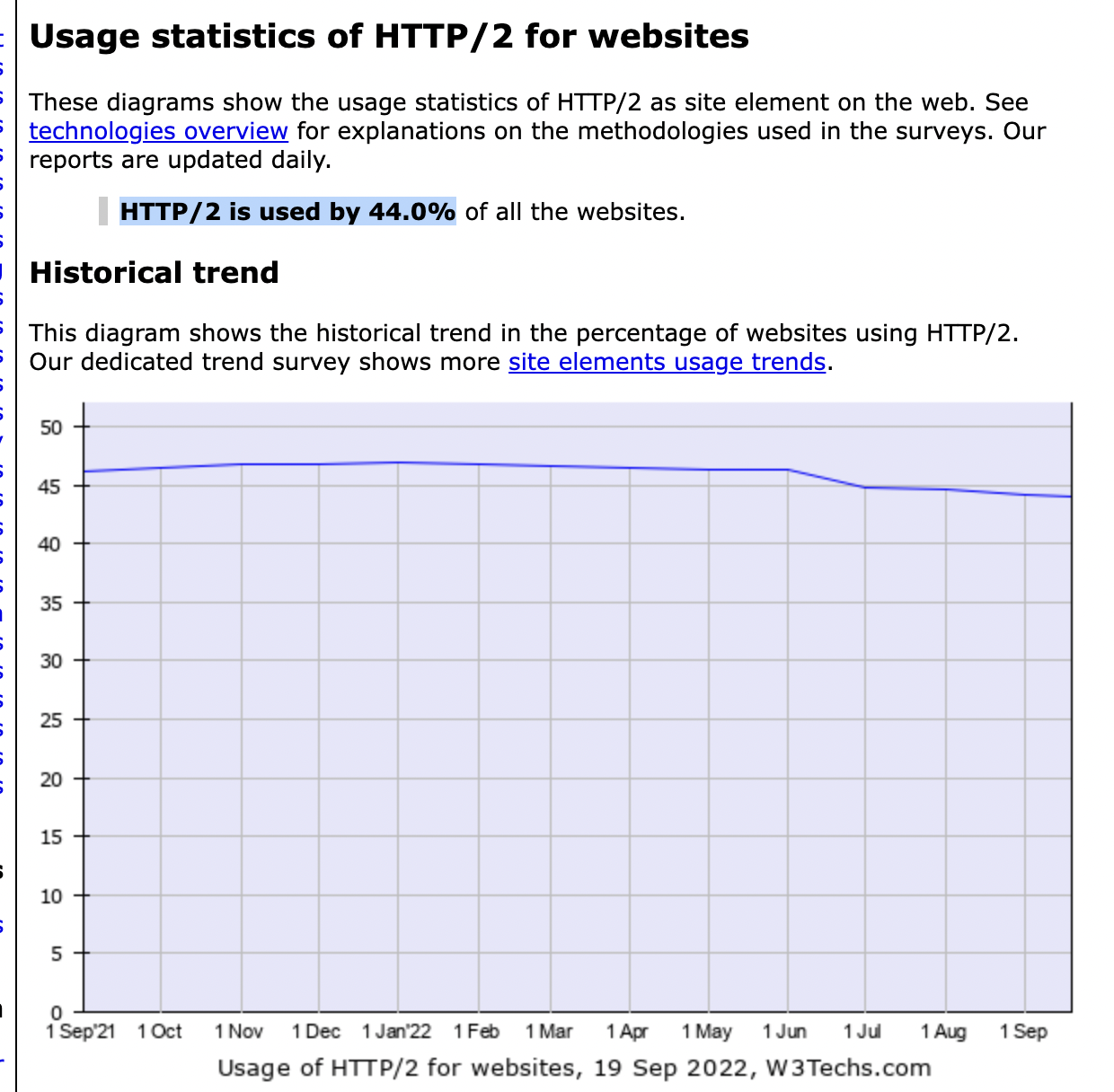
- HTTP2 사용현황 - 2022. 09 기준 44% 사용
8. 웹 구성요소
📝19-22p. 프록시 서버 MDN
프록시, 캐시, 게이트웨이, 터널, 에이전트에 대해서 설명할 수 있다면 이 섹션을 건너뛰어도 좋습니다.
프록시
- 클라이언트와 서버 사이에 위치하여 클라이언트의 요청을 받아 서버에 전달하고, 서버의 응답을 받아 클라이언트에 전달하는 역할을 하는 중간 서버
- 웹 보안, 어플리케이션 통합, 성능 최적화 등의 목적으로 사용
- 일반적으로 크게 주로 2가지 종류의 프록시 서버가 존재
- 포워드 프록시(forward proxy)는 인터넷 상에서 어디로든지 리퀘스트를 전송해주는 프록시
- 주로 캐싱, IP 우회 , 접근 제한 등 으로 사용
- 리버스 프록시(reverse proxy)는 인터넷에서 리퀘스트를 받으면, 내부망 내의 서버로 전송
- 주로 로드밸런싱, 보안 등 으로 사용
- 포워드 프록시(forward proxy)는 인터넷 상에서 어디로든지 리퀘스트를 전송해주는 프록시
- vpn과 forward proxy의 차이?
- 개인 생각으로는 데이터 암호화로, forward proxy가 vpn을 포함하는 더 큰 범주라고 생각
📝19-22p. HTTP 캐싱 MDN
캐시
- 웹 캐시와 캐시 프록시는 자신을 거쳐 가는 리소스 중 자주 찾는 것의 사본을 저장하는 특별한 HTTP 프록시 라고 책에서 설명되고 있음 (7장에서 더 자세하게 설명)
- 클라이언트는 멀리 떨어진 웹 서버보다 근처의 캐시에서 더 빨리 문서를 받을 수 있음
(웹 캐시는 레이턴시와 네트워크 트래픽을 줄여줌) - 캐시 큰 종류는 설(private) 혹은 공유(shared) 캐시 두 가지 부류로 분류
- 공유 캐시는 한 명 이상의 사용자가 재사용할 수 있도록 응답을 저장하는 캐시
- 사설 캐시는 한 명의 사용자만 사용하는 캐시
- 그 외 게이트웨이 캐시, CDN, 리버스 프록시 캐시 그리고 로드 밸랜서 등이 있지만 현재 장에서 생략
- 클라이언트는 멀리 떨어진 웹 서버보다 근처의 캐시에서 더 빨리 문서를 받을 수 있음
브라우저 캐시(Private Cache)
- 사설 캐시는 단일 사용자가 전용으로 사용
- 사용자에 의하여 HTTP를 통해 다운로드된 모든 문서들을 가지고 있음
- 서버에 대한 추가적인 요청 없이 뒤로 가기나 앞으로 가기, 저장, 소스로 보기 등을 위해 방문했던 문서들을 사용
프록시 캐시(Shared Cache)
- 공유 캐시는 한 명 이상의 사용자에 의해 재사용되는 응답을 저장하는 캐시
- 회사의 ISP는 많은 사용자들을 서비스하기 위해 지역 네트워크 기반의 일부분으로서 웹 프록시를 설치가 가능
- 덕분에 조회가 많이 되는 리소스들은 몇 번이고 재사용되어 네트워크 트래픽과 레이턴시를 줄여줌
위 내용 제어를 원한다면 cache-control 헤더를 사용
1 | Cache-Control: private # 단일 사용자만을 위한 것이며 공유 캐시에 의해 저장되어서는 안됨 |
📝19-22p. Proxy servers and tunneling MDN
게이트웨이
- 다른 서버들의 중개자로 동작하는 특별한 서버
- 책에서는 주로 HTTP 트래픽을 다른 프로토콜로 변환하기위해 사용된다고 설명 (ex. HTTP/FTP)
게이트웨이와 프록시에 대한 차이는 모호하긴 하지만, 목적에 대한 차이가 있음
- 게이트웨이는 서로 다른 서버를 연결해주는데 주 목적 (보통 2개 이상의 서버)
- 프록시는 필터링, 보안, 최적화에 등 목적을 갖고 다른 사이트를 대신하며 우회하는데 주 목적 (보통 1개의 서버)
HTTP 터널
- 터널은 두 커넥션 사이에서 raw 데이터를 그대로 전달해주는 HTTP 애플리케이션
- 예시로 HTTP/SSL 터널링이 있음
에이전트
- HTTP 요청을 만들어주는 클라이언트 프로그램(보통 웹 브라우저), 추가로 자동화 스파이더, 웹로봇이 존재 (9장 설명)